nf-core/genomeassembler
Assembly and scaffolding of haploid / unphased genomes from long ONT or PacBio HiFi reads
Introduction
nf-core/genomeassembler is a bioinformatics pipeline that carries out genome assembly, polishing and scaffolding from long reads (ONT or pacbio). Assembly can be done via flye or hifiasm, or combinations of both, polishing can be carried out with medaka (ONT), dorado (ONT only, experimental) or pilon (requires short-reads), and scaffolding can be done using LINKS, Longstitch, both using long-reads, yahs if HiC reads are availble, or RagTag if a reference is available. Quality control includes BUSCO, QUAST and merqury (requires short-reads).
Currently, this pipeline does not implement phasing of polyploid genomes.
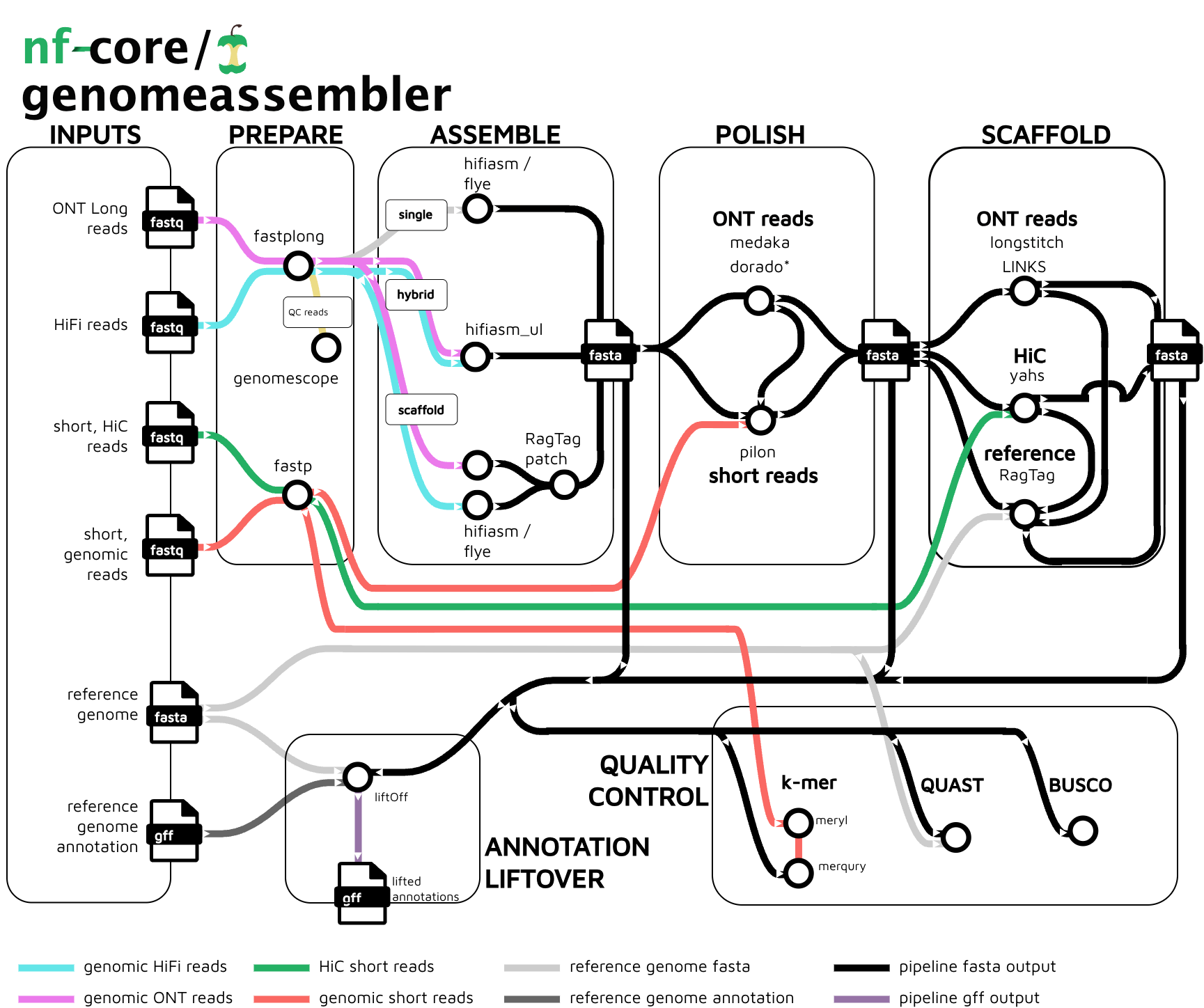

Usage
If you are new to Nextflow and nf-core, please refer to this page on how to set-up Nextflow. Make sure to test your setup with -profile test before running the workflow on actual data.
nf-core/genomeassembler can be set up via pipeline parameters, or via a samplesheet, or a combination of both. For more details and further functionality, please refer to the usage documentation and the parameter documentation.
The pipeline can be run with a test-profile via:
nextflow run nf-core/genomeassembler \ -profile test,<docker/singularity/.../institute> \Please provide pipeline parameters via the CLI or Nextflow -params-file option. Custom config files including those provided by the -c Nextflow option can be used to provide any configuration except for parameters; see docs.
For more details and further functionality, please refer to the usage documentation and the parameter documentation.
Pipeline output
To see the results of an example test run with a full size dataset refer to the results tab on the nf-core website pipeline page. For more details about the output files and reports, please refer to the output documentation.
Credits
nf-core/genomeassembler was written, and is currently maintained by Niklas Schandry, of the Faculty of Biology of the Ludwig-Maximilians University (LMU) in Munich, Germany, with funding support from the German Research Foundation (Deutsche Forschungsgemeinschaft [DFG], via Transregional Research Center TRR356 grant 491090170-A05 to Niklas Schandry).
I thank the following people for constructive reviews and discussion during the development of this pipeline:
- Jim Downie
- Mahesh Binzer-Panchal
- Matthias Hörtenhuber
- Evangelos Karatzas
- Louis Le Nézet
- Júlia Mir Pedrol
- Daniel Straub
Contributions and Support
If you would like to contribute to this pipeline, please see the contributing guidelines.
For further information or help, don’t hesitate to get in touch on the Slack #genomeassembler channel (you can join with this invite).
Citations
If you use nf-core/genomeassembler for your analysis, please cite it using the following doi: 10.5281/zenodo.14986998
An extensive list of references for the tools used by the pipeline can be found in the CITATIONS.md file.
You can cite the nf-core publication as follows:
The nf-core framework for community-curated bioinformatics pipelines.
Philip Ewels, Alexander Peltzer, Sven Fillinger, Harshil Patel, Johannes Alneberg, Andreas Wilm, Maxime Ulysse Garcia, Paolo Di Tommaso & Sven Nahnsen.
Nat Biotechnol. 2020 Feb 13. doi: 10.1038/s41587-020-0439-x.